Featured publications
Recent publications
A complete list is on the publications page.
Links
Machine Learning for Molecules
Our research is on fundamental machine learning methodology for molecules. We develop probabilistic and generative methods to steer chemical synthesis and high-throughput screening, and to learn from natural experiments in humans and the environment.
We aim to advance our basic understanding of how to learn about the molecular world. How can we estimate molecules' effects on complex biological systems? How can we design and synthesize molecules with desired properties? How can we traverse chemical space to find useful molecules?
We investigate these questions from both an applied and a theoretical perspective.
Steering Laboratory Experiments
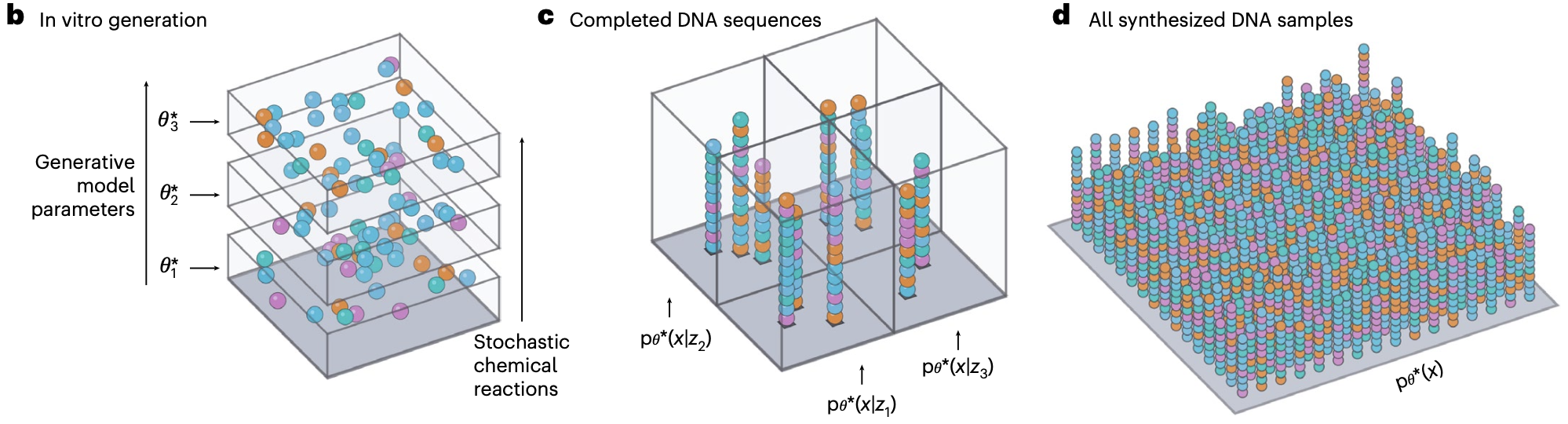
One major line of research is on the co-design of experiments and inference algorithms. We develop new ML methods to actively steer chemical synthesis, optimize high-throughput testing, and improve model learning. This tight integration of laboratory data generation and algorithmic development accelerates molecular discovery. We apply these techniques to design and discover therapeutics, enzymes and more.
We focus especially on methods that exploit the unique properties of molecular systems to overcome the limits of conventional machine learning. We develop algorithms that can apply parallelism at the molecular level to pack more information into experiments. We use these techniques to address challenges such as rare properties, sparse sequence-activity relationships, and discrete combinatorial spaces. This work intersects with experimental design, generative modeling, and laboratory automation.
Learning from Natural Experiments

A second major line of research learns from natural experiments, outside the controlled environment of the laboratory. This includes large-scale evolutionary processes, environmental samples and patient-derived data. We develop ML methods that can learn from natural experiments to design molecules with desired properties.
Generative models have proven to be powerful tools for learning the constraints on molecules imposed by evolution, but their inferences are biased, imperfect and incomplete. We investigate methods that can exploit the scale and diversity of natural experiments to learn the true range of molecular possibilities, and to align flexible generative models with underlying chemistry and biology. We aim to use natural experiments to systematically bridge generalization gaps between the laboratory and the outside world, such as the valley of death between preclinical experiments and clinical trials in humans. This work intersects with causal machine learning, generative modeling, and semiparametric statistics.
Steering Laboratory Experiments ∙ Learning from Natural Experiments ∙ Probabilistic Foundations ∙ PhD Thesis ∙ Older
*Equal contribution ∙ Google Scholar
Steering Laboratory Experiments
- Lifting biomolecular data acquisition A method to pack and extract more information from high throughput experiments, using variational synthesis. Based on an extension of compressed sensing, from learning vectors to learning functions parameterized by neural networks.
- Accelerated learning on large scale screens using generative library models A method to scale up models of protein function via co-design of data collection and inference algorithms, taking advantage of variational synthesis to accelerate learning.
- Manufacturing-aware generative model architectures enable biological sequence design and synthesis at petascale A method that reduces the cost of synthesizing proteins designed by a generative model by as much as a trillion-fold. Best paper award (top 4) at MoML 2024.
- Optimal design of stochastic DNA synthesis protocols based on generative sequence models An experimental design method to efficiently manufacture samples from generative models in the real world.
- Co-evolution of interacting proteins through non-contacting and non-specific mutations One of the first deep mutational scans of a protein-protein interaction.
Learning from Natural Experiments
- Geometric causal models Methods to draw causal inferences from non-iid data, using symmetry, geometry and group theory.
- Hierarchical causal models Methods to draw causal inferences from nested data.
- Estimating the causal effects of T cell receptors Estimating the effect of T cells with a specific TCR on patient outcomes, using hierarchical causal models.
- ProGen2: exploring the boundaries of protein language models Exploration of very large scale generative sequence models trained on massive sequence datasets.
- Non-identifiability and the blessings of misspecification in models of molecular fitness and phylogeny Analysis of the fundamental limits of generative sequence models for protein evolution. Oral presentation at NeurIPS.
- A structured observation distribution for generative biological sequence prediction and forecasting An observation distribution for biological sequences enabling regression from covariates to sequences, applied to forecasting viral antigen evolution.
Probabilistic Foundations
- Adaptive nonparametric perturbations of parametric Bayesian models A technique to robustify Bayesian models, guarding against model misspecification while preserving data efficiency.
- Biological sequence kernels with guaranteed flexibility Analysis of the flexibility of kernels for biological sequences, with fixes enabling consistent nonparametric regression and two-sample tests. Best student paper, NESS 2023.
- Bayesian Empirical Bayes: Simultaneous Inference from Probabilistic Symmetries Methods to reconstruct latent variables from complex structured data, leveraging group theory.
- A kernelized Stein discrepancy for biological sequences A new discrepancy for biological sequence distributions, usable for measuring goodness-of-fit or sample quality of generative sequence models.
- Bayesian data selection A technique to discover which aspects of a data set a Bayesian model can explain. Best student paper, NESS 2021.
- A generative nonparametric Bayesian model for whole genomes A scalable nonparametric model for biological sequences with established asymptotic consistency and convergence rate.
PhD Thesis
- Generative Statistical Methods for Biological Sequences
Older
- All-optical electrophysiology for high-throughput functional characterization of a human iPSC-derived motor neuron model of ALS A high-throughput screening platform for measuring electrophysiological properties of human neurons.
- Genetically targeted all-optical electrophysiology with a transgenic Cre-dependent optopatch mouse A transgenic mouse for optical electrophysiology studies in genetically-defined subsets of cells.
Principal Investigator
-

Assistant Professor, DTU Chemistry.
Affiliations: DTU Department of Chemistry ∙ Jura Bio
Office: Building 206, Room 258, Kemitorvet, 2800 Kgs. Lyngby
Email: enawe [at] dtu.dk ∙ Brief bio (plain text)
PhD Students

Join Us
I am always looking for motivated students, postdocs, and collaborators interested in probabilistic machine learning and its applications to the molecular sciences. Please reach out if you are interested: enawe [at] dtu.dk
ML and Molecules Reading Group — Spring 2026

The ML & Molecules reading group covers fundamental machine learning methodology and its intersection with the molecular sciences. This semester we are covering two interrelated topics: first, the interface of machine learning and simulation, and second, experimental design and planning in the time domain. Our goal is to understand how to model the dynamics of chemical and biological systems, and their response to perturbation.
Large scale computing has transformed scientific discovery both through physical simulation and through machine learning. Yet these two forms of scientific computing sit in uneasy relationship, operating with distinct logic and methodology. We will investigate the interface between machine learning and simulation.
Next, we turn our attention to the implications of these models for experimental design. Current machine learning techniques for molecular discovery typically rely on separate controlled experiments of different molecules. These techniques are often bottlenecked in throughput. We study alternative experimental designs that test the effects of different interventions by turning them on or off over time. In these experiments, the time dynamics of the system set the speed of information gain. To analyze these experiments, we must understand systems' response to perturbations, and leverage them to create new experimental protocols.
Thursdays 1–2:30 pm, Building 207 Room 222 (DTU Chemistry). First meeting: February 5. Sign up for the mailing list.
- Feb. 5: Fast sampling from energy-based models for molecular systems. Noé et al. 2019. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning. link
- Feb. 12: Learning energy-based models. Hyvärinen. 2005. Estimation of non-normalized statistical models by score matching. link
- Feb. 19: Learning, sampling and simulating trajectories with energy-based models for molecular systems. Plainer et al. 2025. Consistent Sampling and Simulation: Molecular Dynamics with Energy-Based Diffusion Models. link
- Feb. 26: Learning in implicit generative models. Mohamed and Lakshminarayanan. 2016. Learning in implicit generative models. link
- Mar. 5: Learning energy-based models for molecular systems by learning forces. Kabylda et al. 2025. Molecular Simulations with a Pretrained Neural Network and Universal Pairwise Force Fields. link
- Mar. 12: Inference in implicit models with simulation based inference. Papamakarios and Murray. 2016. Fast ε-free Inference of Simulation Models with Bayesian Conditional Density Estimation. link
- Mar. 19: Adaptive experiments in time. Glynn et al. 2020. Adaptive Experimental Design with Temporal Interference: A Maximum Likelihood Approach. link
- Mar. 26: N-of-1 experiments. Liang and Recht. 2023. Randomization Inference When N Equals One. link
- Apr. 16: Time dynamics of cells and populations. Schiebinger et al. 2019. Optimal-Transport Analysis of Single-Cell Gene Expression Identifies Developmental Trajectories in Reprogramming. link
- Apr. 23: Time dynamics of cells in response to perturbation. Lorch et al. 2026. Latent Causal Diffusions for Single-Cell Perturbation Modeling. link
- Apr. 30: Representing perturbations and high-dimensional responses. Lopez et al. 2023. Learning Causal Representations of Single Cells via Sparse Mechanism Shift Modeling. link
- May 21: Learning differential equation models. Raissi et al. 2017. Physics Informed Deep Learning (Part I): Data-driven Solutions of Nonlinear Partial Differential Equations. link
- May 28: Learning chemical kinetics. Gusmao et al. 2021. Kinetics-Informed Neural Networks. link
About ML & Molecules: ML & Molecules is a reading group organized by Asst. Prof. Eli Weinstein (DTU Chemistry) and Assoc. Prof. Jes Frellsen (DTU Compute). It focuses on fundamental probabilistic machine learning and its intersection with the molecular sciences. Everyone in the group presents a paper, in a rotating schedule. It is open to students, postdocs, faculty and staff. It is not a formal course, but can optionally be taken as a project course for course credit. Contact: enawe [at] dtu.dk
ML and Molecules Reading Group — Fall 2025

Machine learning and AI have transformed scientific data analysis. But the experiments that generate data are usually taken as given. Better algorithmic control of scientific experiments could lead to better learning, enabling the next generation of scientific AI.
This semester, we studied the fundamental theory of experimental design. We read foundational statistical ideas about how to quantify the amount of information an experiment provides, studied emerging ML methods and algorithms for optimizing experimental designs, and looked at how these ideas are being applied in science, with a focus on protein design and engineering.
Thursdays 1–2:30 pm, Room 207-222 (DTU Chemistry). First meeting: September 25. Sign up for the mailing list.
Reading List
- Introduction and overview. Rainforth et al. 2024. Modern Bayesian Experimental Design. link
- Lindley's foundational paper. D.V. Lindley. 1956. On a Measure of the Information Provided by an Experiment. link
- Experimental design for protein design. Romero et al. 2012. Navigating the protein fitness landscape with Gaussian processes. link
- Advances in experimental design for proteins. Frey et al. 2025. Lab-in-the-loop therapeutic antibody design with deep learning. link
- Optimizing designs with stochastic gradients. Foster et al. 2020. A Unified Stochastic Gradient Approach to Designing Bayesian-Optimal Experiments. link
- Building training datasets with large scale screens. Krishnan et al. 2025. A generative deep learning approach to de novo antibiotic design. link
- Optimal information gathering for prediction. Smith et al. 2023. Prediction Oriented Bayesian Active Learning. link
- Compressed screens. Liu et al. 2024. Scalable, compressed phenotypic screening using pooled perturbations. link
- Stochastic variational design for compressed experiments. Grover and Ermon. 2019. Uncertainty Autoencoders. link
- Information for optimization. Russo and van Roy. 2014. Learning to Optimize via Information-Directed Sampling. link
- Optimal nonparametric design and theory. Huszar and Duvenaud. 2012. Optimally-Weighted Herding is Bayesian Quadrature. link
About ML & Molecules: ML & Molecules is a reading group organized by Asst. Prof. Eli Weinstein (DTU Chemistry) and Assoc. Prof. Jes Frellsen (DTU Compute). It focuses on fundamental probabilistic machine learning and its intersection with the molecular sciences. Everyone in the group presents a paper, in a rotating schedule. It is open to students, postdocs, faculty and staff. It is not a formal course, but can optionally be taken as a project course for course credit. Contact: enawe [at] dtu.dk